Раньше Google понижал в выдаче веб-страницы с маленьким количеством входящих ссылок. Скоро он научится «наказывать» страницы с текстом, который содержит недостоверные факты. Это следует из научной работы “Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources” от сотрудников Google.

Им удалось разработать систему, которая автоматически извлекает факты с веб-страниц, отличает ошибки парсинга от фактологических ошибок в тексте, а затем вычисляет уровень достоверности текста (оценка KBT, Knowledge-Based Trust). Эта оценка иногда является более объективным показателем, что рейтинг PageRank (по крайней мере, рейтинг KBT способен уточнить значение PageRank). Например, у сайтов с «жёлтыми» новостями часто больший рейтинг PageRank, потому что на них много входящих ссылок из-за вирусности контента. Но в то же время их нельзя считать надёжным источником информации.
Для извлечения фактов использовались наработки проекта Knowledge Vault (KV), который применяет 16 различных методов извлечения триад данных (субъект, утверждение, объект) с веб-страниц. Субъект и утверждение принадлежат к множеству из краудсорсинговой базы знаний Freebase, а объект может быть сущностью, числом, датой или строкой.
Триада считалась «правдивой», если она в полном составе присутствует в базе Freebase. Если же там есть субъект и утверждение, а значение объекта иное, то факт считался ложным. Если пара из субъекта и утверждения отсутствует в базе, то такую триаду исключали из выборки.
Ошибки парсинга отличали по нескольким признакам: 1) субъект = объект; 2) субъект или объект не соответствует требованиям; 3) объект находится за пределами диапазона значений (например, вес спортсмена более 500 кг).
Исследователям удалось значительно улучшить результат работы Knowledge Vault. Кроме вышеупомянутого разграничения ошибок парсинга и фактических ошибок, они также сделали более сложную модель, которая умеет учитывать рейтинг нескольких страниц с одного веб-сайта, а не каждой страницы по отдельности. Дело в том, что по отдельности качественно вычислять рейтинг не всегда получается: так, для более миллиарда веб-страниц KV сумела извлечь только по одной триаде данных, а с некоторых страниц — десятки тысяч триад.
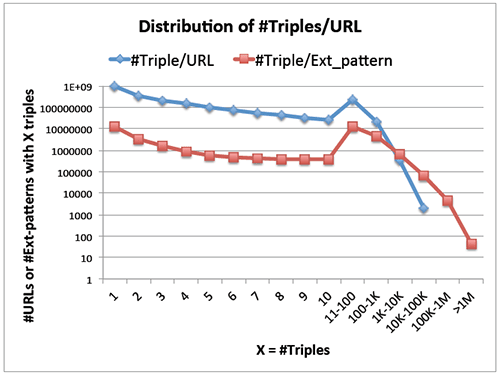
Технологию проверили на выборке в 119 млн веб-страниц и 5,6 млн веб-сайтов, которые сравнили с базой 2,9 млрд фактов, собранных из интернета. Такое масштабное тестирование подобных систем тоже проведено впервые. Ручная проверка показала, что автоматическое KBT-рейтингование работает хорошо.
Интересно, что PageRank и KBT зачастую являются ортогональными сигналами. Так, высокий PR и низкий KBT характерен для «жёлтых» СМИ из этого списка и веб-форумов.
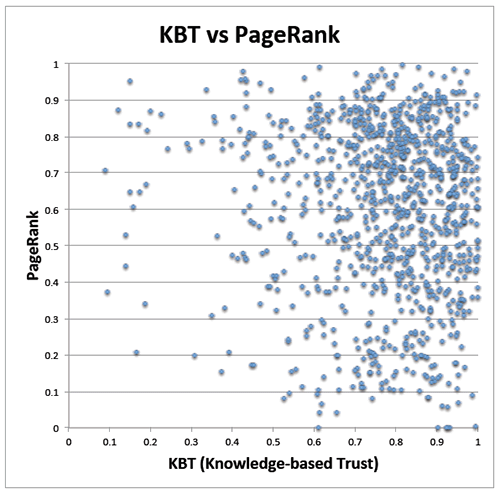
Результаты работы предложено использовать для улучшения объективности PageRank, но они могут найти применение и в некоторых других задачах по дата-майнингу.
Взято с Xakep.ru