
«Фундаментальна ідея дослідження полягає в тому, що якщо ви віддаєте критично важливі системи в руки штучного інтелекту та алгоритмів, ви також повинні навчитися готуватися до їхньої невдачі», — говорить Мілляхо.
Це не обов’язково небезпечно, якщо служба потокового передавання пропонує користувачам нецікаві параметри, але така поведінка підриває довіру до функціональності системи. Однак збої в більш критичних системах, які покладаються на машинне навчання, можуть бути набагато шкідливішими.
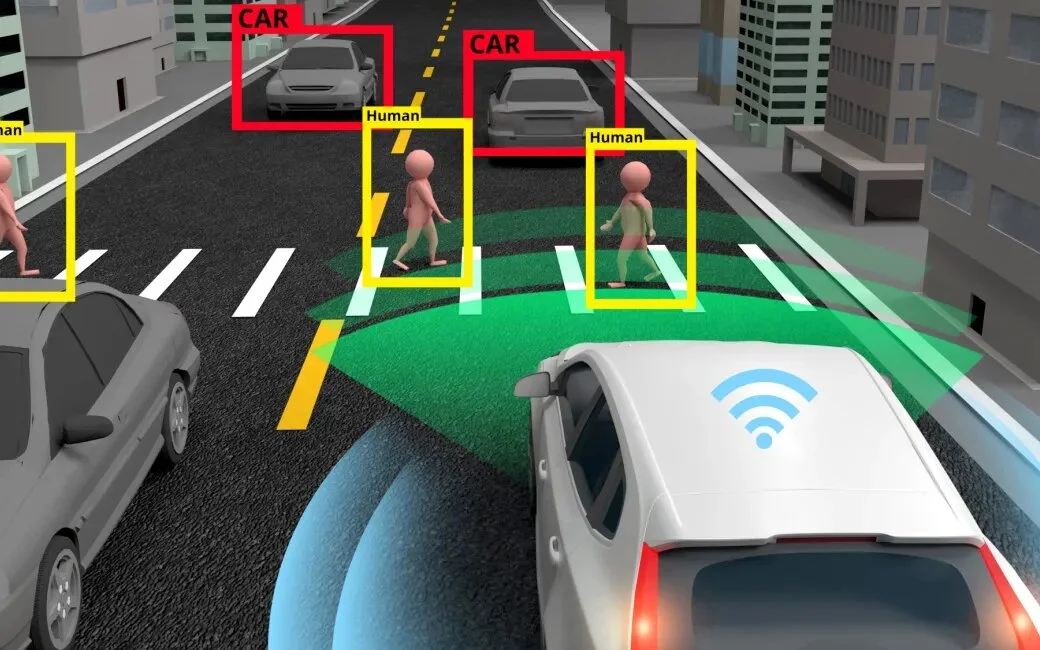
«Я хотів дослідити, як підготуватися, наприклад, до того, що комп’ютерний зір неправильно ідентифікує речі. Наприклад, у комп’ютерній томографії штучний інтелект може ідентифікувати об’єкти в розділах. Якщо трапляються помилки, це викликає питання про те, наскільки комп’ютерам слід довіряти в таких питаннях. , і коли попросити людину поглянути», — каже Мілляхо.
Чим критичнішою є система, тим релевантнішою є здатність мінімізувати пов’язані з нею ризики.
Більш складні системи породжують все більш складні помилки
Окрім Мілляхо, дослідження проводили Мікко Раатікайнен, Томі Мянністе, Юкка К. Нурмінен і Томмі Мікконен. Видання побудовано навколо експертних інтерв’ю.
«Архітекторів програмного забезпечення опитали щодо дефектів і неточностей у моделях машинного навчання та навколо них. Ми також хотіли з’ясувати, які варіанти дизайну можна зробити, щоб запобігти помилкам», — каже Мілляхо.
Якщо моделі машинного навчання містять пошкоджені дані, проблема може поширитися на системи, у реалізації яких використовувалися моделі. Також необхідно визначити, які механізми підходять для виправлення помилок.
«Структури мають бути розроблені таким чином, щоб запобігти ескалації радикальних помилок. Зрештою, серйозність, до якої може прогресувати проблема, залежить від системи».
Наприклад, людям легко зрозуміти, що з автономними транспортними засобами система потребує різноманітних механізмів безпеки та безпеки. Це також стосується інших рішень штучного інтелекту, які потребують правильного функціонування безпечних режимів.
«Ми маємо дослідити, як забезпечити, щоб за різних обставин штучний інтелект функціонував належним чином, тобто відповідно до людської раціональності. Найбільш відповідне рішення не завжди є самоочевидним, і розробники повинні зробити вибір, що робити, коли ви не можете бути впевнені в цьому».
Мілляхо розширив дослідження, розробивши відповідний механізм для виявлення несправностей, хоча він ще не просунувся до фактичного алгоритму.
«Це просто ідея нейронних мереж. Функціональна модель машинного навчання зможе миттєво перемикати робочі моделі, якщо поточна не працює. Іншими словами, вона також повинна мати можливість передбачати помилки або розпізнавати ознаки помилки».
Останнім часом Мілляхо зосередився на завершенні докторської дисертації, тому не може нічого сказати про своє майбутнє в проєкті. Проєкт IVVES під керівництвом Юкки К. Нурмінена продовжить роботу з перевірки безпеки систем машинного навчання.




Comments