
Дослідники використовують тіні для моделювання 3D-сцен, включаючи об’єкти, заблоковані для перегляду. Ця техніка може призвести до створення безпечніших автономних транспортних засобів, ефективніших гарнітур AR/VR або швидших складських роботів.
Уявіть, що ви проїжджаєте тунелем на автономному транспортному засобі, але без вашого відома аварія зупинила рух попереду. Зазвичай вам потрібно покладатися на автомобіль попереду, щоб знати, що вам слід почати гальмувати. Але що, якби ваш транспортний засіб бачив автомобіль попереду й гальмував ще раніше?
Дослідники з Массачусетського технологічного інституту та Meta розробили техніку комп’ютерного бачення, яка колись дозволить автономному транспортному засобу робити саме це. Вони запровадили метод, який створює фізично точні 3D-моделі цілої сцени, включаючи зони, заблоковані для перегляду, використовуючи зображення з однієї камери. Їх техніка використовує тіні, щоб визначити, що знаходиться в закритих частинах сцени.
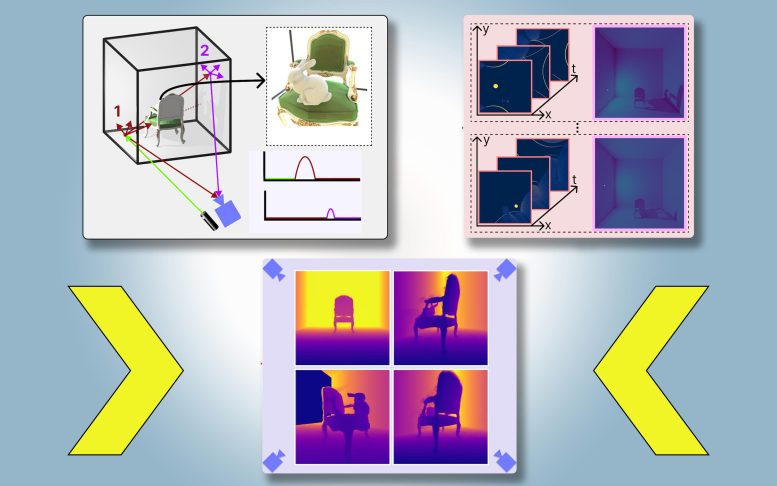
Вони називають свій підхід PlatoNeRF, заснований на платонівській алегорії печери, уривку з «Республіки» грецького філософа, в якому в’язні, закуті в печеру, бачать реальність зовнішнього світу на основі тіней, що відкидають стіни печери.
Поєднуючи лідар (виявлення світла та визначення дальності) з машинним навчанням, PlatoNeRF може генерувати більш точні реконструкції 3D-геометрії, ніж деякі існуючі методи ШІ. Крім того, PlatoNeRF краще справляється з плавною реконструкцією сцен, де важко розгледіти тіні, наприклад сцени з високим освітленням або темним фоном.
Покращення AR/VR і робототехніки за допомогою PlatoNeRF
На додаток до підвищення безпеки автономних транспортних засобів, PlatoNeRF може зробити гарнітури AR/VR більш ефективними, дозволяючи користувачеві моделювати геометрію кімнати без необхідності ходити навколо, проводячи вимірювання. Це також може допомогти роботам-складам швидше знаходити предмети в захаращеному середовищі.
«Наша ключова ідея полягала в тому, щоб взяти ці дві речі, які робили в різних дисциплінах раніше, і об’єднати їх разом — мультибаунс-лідар і машинне навчання. Виявляється, коли ви об’єднуєте ці два світи, ви знаходите багато нових можливостей для дослідження та отримання найкращого з обох світів», – каже Цофі Клінгхоффер, аспірант Массачусетського технологічного інституту з медіа-мистецтва та наук, асистент наукового відділу Camera Culture Group медіа-лабораторії MIT і провідний автор статті про PlatoNeRF.
Клінгхоффер написав статтю разом зі своїм радником Рамешем Раскаром, доцентом кафедри медіа-мистецтва та наук і керівником групи культури камери в MIT; старший автор Ракеш Ранджан, директор з досліджень ШІ в Meta Reality Labs; а також Сіддхарт Сомасундарам, науковий співробітник Camera Culture Group, і Сяоюй Сян, Юйчен Фан і Крістіан Річардт з Meta. Дослідження буде представлено на конференції з комп’ютерного зору та розпізнавання образів.
Розширена 3D-реконструкція за допомогою лідара та машинного навчання
Реконструкція повної 3D-сцени з однієї погляду камери є складною проблемою. Деякі підходи до машинного навчання використовують генеративні моделі штучного інтелекту, які намагаються вгадати, що знаходиться в закритих областях, але ці моделі можуть галюцинувати об’єкти, яких насправді немає. Інші підходи намагаються визначити форми прихованих об’єктів за допомогою тіней на кольоровому зображенні, але ці методи можуть мати проблеми, коли тіні важко побачити.
Для PlatoNeRF дослідники Массачусетського технологічного інституту побудували ці підходи, використовуючи нову модель зондування, яка називається однофотонним лідаром . Лідари відображають 3D-сцену, випромінюючи імпульси світла та вимірюючи час, який потрібен цьому світлу, щоб відскочити назад до датчика. Оскільки однофотонні лідари можуть виявляти окремі фотони, вони забезпечують дані з вищою роздільною здатністю.
Дослідники використовують однофотонний лідар для освітлення цільової точки на сцені. Частина світла відбивається від цієї точки та повертається прямо до датчика. Однак більшість світла розсіюється та відбивається від інших об’єктів, перш ніж повернутися до датчика. PlatoNeRF покладається на ці другі відбивання світла.
Розраховуючи, скільки часу потрібно світлу, щоб двічі відбитися, а потім повернутися до лідарного датчика, PlatoNeRF фіксує додаткову інформацію про сцену, включаючи глибину. Другий відбій світла також містить інформацію про тіні.
Система відстежує вторинні промені світла — ті, що відбиваються від цільової точки до інших точок сцени — щоб визначити, які точки лежать у тіні (через відсутність світла). На підставі розташування цих тіней PlatoNeRF може зробити висновок про геометрію прихованих об’єктів.
Лідар послідовно висвітлює 16 точок, захоплюючи кілька зображень, які використовуються для реконструкції всієї 3D-сцени.
«Щоразу, коли ми освітлюємо точку сцени, ми створюємо нові тіні. Оскільки у нас є всі ці різні джерела освітлення, ми маємо багато світлових променів, що стріляють навколо, тому ми вирізаємо область, яка закрита та лежить за межами видимого ока», — каже Клінгхоффер.
Поєднання мультибаунсового лідара та полів нейронного випромінювання
Ключем до PlatoNeRF є поєднання мультибаунсового лідара з особливим типом моделі машинного навчання, відомої як поле нейронного випромінювання (NeRF). NeRF кодує геометрію сцени у вагові коефіцієнти нейронної мережі, що дає моделі потужну здатність інтерполювати або оцінювати нові види сцени. Ця здатність до інтерполяції також призводить до високоточних реконструкцій сцени в поєднанні з мультивідбійним лідаром, говорить Клінгхоффер.
«Найбільшою проблемою було з’ясувати, як поєднати ці дві речі. Нам справді потрібно було подумати про фізику того, як світло передається за допомогою лідара з багаторазовим відскоком, і як моделювати це за допомогою машинного навчання», — каже він.
Вони порівняли PlatoNeRF з двома звичайними альтернативними методами: один використовує лише лідар, а інший – лише NeRF із кольоровим зображенням.
Вони виявили, що їхній метод зміг перевершити обидва методи, особливо коли лідарний датчик мав нижчу роздільну здатність. Це зробить їхній підхід більш практичним для розгортання в реальному світі, де датчики з нижчою роздільною здатністю поширені в комерційних пристроях.
«Приблизно 15 років тому наша група винайшла першу камеру, яка «бачить» за кутами, яка працює, використовуючи численні відбиття світла або «відлуння світла». Ці методи використовували спеціальні лазери та датчики, а також використовували три відбиття світла. З тих пір технологія лідарів стала більш популярною, що призвело до наших досліджень камер, які бачать крізь туман. Ця нова робота використовує лише два відбиття світла, що означає, що співвідношення сигнал/шум дуже високе, а якість 3D-реконструкції вражаюча», — каже Раскар.
У майбутньому дослідники хочуть спробувати відстежити більше двох відскоків світла, щоб побачити, як це може покращити реконструкцію сцени. Крім того, вони зацікавлені в застосуванні більш глибоких методів навчання та поєднанні PlatoNeRF з вимірюваннями кольорових зображень для отримання інформації про текстуру.
«Хоча зображення тіней, зроблені камерою, давно вивчаються як засіб 3D-реконструкції, ця робота повертається до проблеми в контексті лідара, демонструючи значні покращення в точності реконструйованої прихованої геометрії. Робота показує, як розумні алгоритми можуть створювати надзвичайні можливості в поєднанні зі звичайними датчиками, включаючи лідарні системи, які багато хто з нас зараз носить у кишені», — каже Девід Лінделл, доцент кафедри комп’ютерних наук Університету Торонто. який не брав участі в цій роботі.


