
Компанія Google розробила ШІ-систему “оцінки фактів на основі пошукової видачі ” (Search-Augmented Factuality Evaluator, SAFE), завдання якої знаходити помилки у відповідях сервісів на базі великих мовних моделей (LLM) на кшталт ChatGPT.
LLM використовуються в різних цілях, аж до написання наукових праць, проте вони нерідко помиляються, наводячи недостовірні відомості, і навіть наполягаючи на їхній істинності (галюцинуючи). Нова розробка команди Google DeepMind виокремлює з виведення нейромережі окремі факти, формує запит до пошукової системи та намагається знайти підтвердження викладених відомостей.
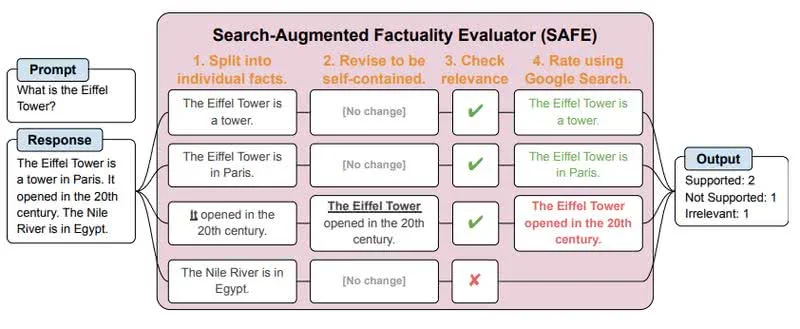
Під час тестування SAFE перевірила 16 тисяч відповідей кількох сервісів на базі великих мовних моделей, серед яких Gemini, ChatGPT, Claude та PaLM-2, після чого дослідники порівняли результати з висновками людей, які робили це вручну. Висновки SAFE на 72% збіглися з думками людей, причому під час аналізу розбіжностей у 76% істина опинялася за ШІ.
Код SAFE опубліковано на GitHub і доступний всім бажаючим перевірити надійність відповідей LLM.