


Використовуючи просторовий модулятор світла і невеликий набір параметрів, що програмуються, вчені проводили нелінійно-оптичні обчислення всередині багатомодових волокон. Підсумкова продуктивність роботи їх мережі була порівнянна з нейромережами з більш ніж 100 разів великою кількістю параметрів.
Сучасні генеративні моделі штучного інтелекту використовують сотні мільярдів параметрів на вирішення дедалі складніших завдань. Навчання нейромереж таких масштабів вимагає величезних обчислювальних потужностей, які можуть бути надані лише центрами обробки даних завбільшки з ангар, що споживають енергію, еквівалентну потребам в електриці середнього за розміром міста. Наприклад, на навчання мовної моделі GPT-3, яка має 175 мільярдів параметрів, було витрачено 1,3 гігават-години електроенергії, що достатньо для повної зарядки 13 тисяч автомобілів Tesla Model S.
Для сталого розвитку штучного інтелекту в його нинішньому темпі виникає необхідність переосмислити як самі алгоритми машинного навчання, так і обчислювальне обладнання. Одним із рішень може стати оптична апаратна реалізація архітектури нейронних мереж, тобто перехід від опори на суто транзисторні обчислювальні потужності до систем на оптоволоконній основі. У новому дослідженні, опублікованому в журналі Advanced Photonics, група вчених розробила таку нейромережу.
Запропонована архітектура поєднує оптичну складову з невеликою кількістю програмованих у цифровому вигляді параметрів. За допомогою методу, відомого як формування хвильового фронту, дослідники керували ультракороткими імпульсами в багатомодових волокнах – це волокна з великим діаметром серцевини, що проводять промені світла завдяки ефекту повного внутрішнього відбиття. Такі оптичні волокна підтримують кілька поперечних мод для заданої оптичної частоти та поляризації. З їх допомогою вчені здійснювали нелінійно-оптичні обчислення із середньою оптичною потужністю, що вимірюється лише в мікроватах.

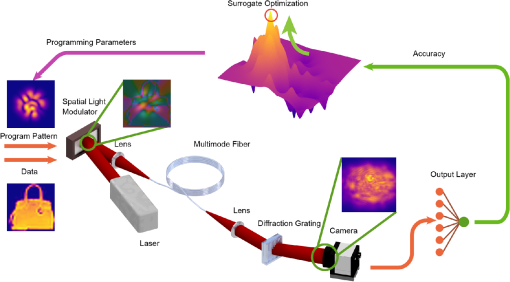
В результаті продуктивність для завдання класифікації зображень була порівнянна з цифровими системами на транзисторній основі, що мають у 100 разів більше параметрів при однаковому рівні точності. Вчені зменшили кількість параметрів моделі на 97 відсотків, що призвело до загального скорочення цифрових операцій на 99 відсотків порівняно з аналогічною цифровою багатошаровою нейронною мережею, яка базується на суто транзисторній апаратній частині. Наприклад, система приблизно з двома тисячами параметрів працювала так само добре, як типова цифрова нейронна мережа з більш ніж 400 тисячами параметрів.
Окремо автори розглянули питання швидкості обчислень їхньої нейромережі, яка визначає підсумкову швидкість отримання висновків від моделі. Для їх варіанта мережі вона невисока та обмежена частотою оновлення рідкокристалічного просторового модулятора світла. Це обмеження можна подолати, перейшовши на швидший метод формування хвильового фронту: наприклад, якщо використовувати комерційні цифрові мікродзеркальні пристрої та квадрантні фотодіоди – це фотодіоди, які складаються з чотирьох оптично активних зон (випромінюючі діоди), розділені між собою невеликим проміжком (їх зазвичай використовують визначення положення лазерних променів один щодо одного).
Реалізуючи ту ж архітектуру оптичних обчислень з набором комерційно доступного високошвидкісного обладнання, можна було б досягти продуктивності 25 терафлопс в секунду при загальному енергоспоживанню 12,6 Вт, що значно нижче, ніж споживання в 300 Вт класичним транзисторним графічним процесором з порівнянною.
Привертає увагу величезний розрив у можливостях нейромереж на оптичній елементній базі і на класичній транзисторній. Якщо його вдасться перенести в серійні комерційні рішення, то саме перші, мабуть, стануть майбутнім у розвитку великих мовних моделей, подібних до GPT-4.



