Эта технология находит применение в военных системах связи, в диспетчерских службах, а также в системах пейджерной связи. Разработчики преобразователей голоса учли особенности работы горла, голосовых связок и всего речевого аппарата. Звонкие и глухие звуки воспроизводятся здесь различными способами (с помощью импульсного генератора и генератора шума, соответственно). Блок-схема преобразователя звука типа вокодер показана на рис. 2.4.2.1. Исходный спектр человеческого голоса здесь делится на ряд субдиапазонов (на рис. 2.4.2.1 их число равно16) по 200 Гц каждый. Эти субдиапазоны выделяются узкополосными фильтрами, за которыми следуют выпрямители и фильтры низких частот (20 Гц). Выходные сигналы этих фильтров мультиплексируются и преобразуются в цифровую форму. Частота стробирования этих сигналов составляет примерно 50 Гц. Разрядность АЦП в этом случае может составлять 3 бита. На принимающей стороне осуществляется цифро-аналоговое преобразование (ЦАП) и мультиплексирование. Сбалансированные амплитудные модуляторы, управляемые ЦАП и переключателем, выдают сигналы на узкополосные фильтры. Все эти сигналы смешиваются в сумматоре, а результат воспроизводится.
Не трудно видеть, что в случае схемы, показанной на рис. 2.4.2.1, необходимое быстродействие передающей линии составляет 3 бита * 50 Гц * 16 каналов = 2,4 Кбит/с. Дальнейший выигрыш может быть получен за счет цифрового сжатия. Число каналов (фильтров) и ширина пропускаемой полосы частот может варьироваться, соответственно будет меняться и качество воспроизведения звука. Минимально возможная полоса пропускания передающей линии, при которой значение передаваемого текста еще воспринимается правильно, лежит ниже 1 Кбит/с.
Предшествующая фраза, включая пробелы и знаки препинания, содержит около 150 символов. Для ее произношения требуется около 10 сек (15 символов в сек). Но даже вокодеру потребуется для этого предложения передать не менее 10000 бит. Откуда такое отличие? Во-первых, человеческая речь индивидуальна и эта фраза, произнесенная разными людьми, будет звучать по-разному, кроме того, существует эмоциональная окраска, которой практически лишена буквенная запись. Во-вторых, даже самая совершенная современная система сжатия звуковой информации не идеальна и остается широкое поле для дальнейшего совершенствования. Пути могут быть разными в зависимости от поставленной задачи. Если требуется передать только информацию, следует преобразовать звук в символьную (буквенную) форму, передать эти данные в цифровом виде, а на принимающей стороне осуществить обратное преобразование. Само буквенное представление может быть также подвергнуто некоторому сжатию, но это неизбежно увеличит задержку воспроизведения. В сущности, данная схема является развитием идей, заложенных в вокодере.
В случае необходимости передачи индивидуальных особенностей голоса, сначала должен проводиться анализ этих персональных отличий. Особенности голоса в закодированном виде передаются принимающей стороне, где эти данные используются в дальнейшем при воспроизведении закодированного текста. Эти схемы потребуют довольно мощных сигнальных процессоров и, вероятно, найдут применение лишь в следующем веке.
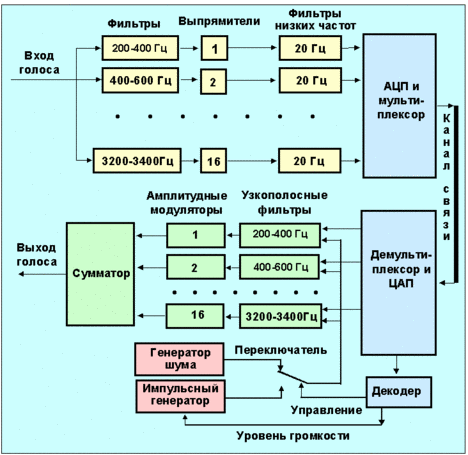
Рис. 2.4.2.1. Блок-схема кодирования/декодирования человеческого голоса (Vocoder)
Взято с citforum.ru
